

평소에 백준 사이트에서 PS 문제를 푸는 것을 좋아한다. 알고리즘을 공부하는 것 자체만으로도 재미있고, 코딩 테스트를 언제든 준비할 수 있게끔 녹슬지 않게 실력을 가꾸기 위해서이다. 직접 백준 문제를 풀면서 파이썬을 통해 백준 문제를 풀 때 알아두면 좋은 것들을 정리하려고 한다. 이번 포스팅에서 다루는 것은 파이썬으로 백준 문제를 풀 때에 꼭 알아두어야 맞왜틀( 맞았는데 왜 틀리지 )을 방지할 수 있을만한 내용들이다.
본론
시간복잡도 계산
알고리즘을 푼다라고 하면 가장 기본적인 것은 시간복잡도 계산이다. 알고리즘에는 다양한 것들이 있지만, 우리가 기본적으로 사용하는 알고리즘의 시간 복잡도를 알고 있다고 가정하자. ( 예를 들어 이진 탐색의 시간 복잡도가 O(logN)이라는 것을 알고 있다 ) 그리고 다음 문제를 살펴보자.
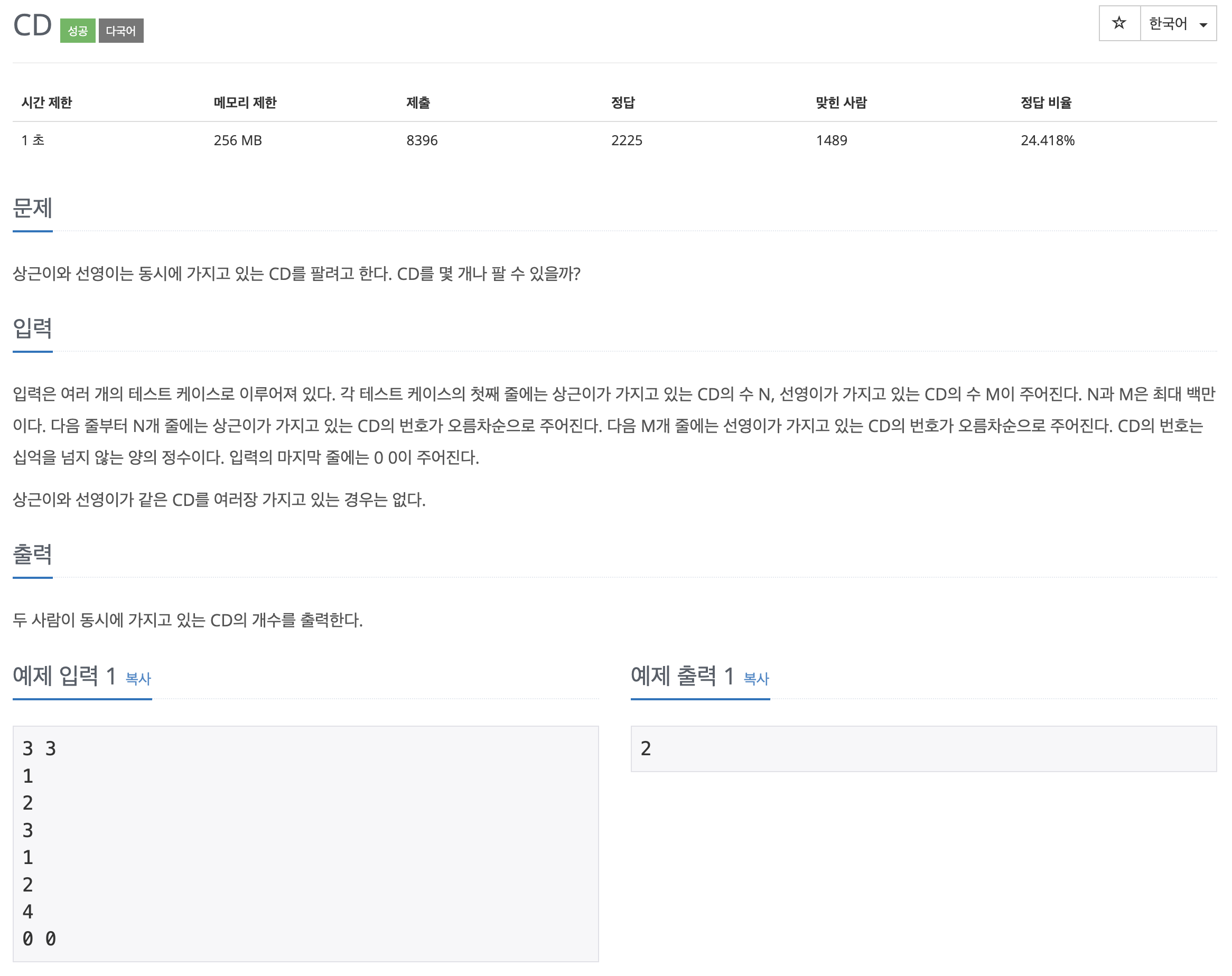
얼핏 보면 간단하게 풀 수 있을 것 같아 보인다. 상근이와 선영이가 가진 CD 번호를 비교해서 같은 게 몇개인 지 알 수 있지 않을까, 이중 포문을 써서 비교하면 되지 않을까?
하지만 시간 제한이 1초인데 반해, N과 M은 각각 백만의 가짓수가 나온다. 백만은 10^6에 해당하는 수치라는 것을 생각하자. 이 문제를 이중 포문으로 풀게 된다면 최악의 경우에는 10^12번의 처리를 해야 한다.
여기서 기억할 가장 중요한 포인트는 python3는 1초에 10^8번의 처리를 할 수 있다. 따라서 이중 포문으로 풀게 된다면 시간 초과가 발생할 가능 성이 높으며, 이는 반대로 생각하면 그리디 알고리즘은 아니라는 것이다. ( 매 선택지에서 가장 좋아 보이는 것을 선택하는 알고리즘 )그리고 어느 정도 알고리즘에 익숙한 사람이라면 눈치채겠지만, 이진 탐색 알고리즘 문제라는 것을 쉽게 추측할 수 있다.
이렇게 시간 복잡도를 계산하는 것은 가장 기본적으로 해야할 일이다. 간단하게 그리디 알고리즘으로 풀 수 있는지 없는지 체크할 수 있으며 이를 통해 다른 알고리즘을 써야 한다는 것을 알 수 있다. ( ex. 누적합, 이진탐색 등.. )
sys.stdin.readline()
이번에 소개할 내용은 sys모듈에 탑재되어있는 stdin.readline() 메서드이다. 파이썬에서의 input() 함수는 내부적으로 stdin.readline()을 호출한 다음 개행문자인 \n를 제거하는 일을 한다. 따라서 약간의 오버헤드가 발생하기 때문에 시간초과가 발생하는 경우가 있다.
print(input()) # Hello, world!를 입력
# Hello, world!
sys 모듈에 존재하는 stdin.readline()을 사용하면 input()보다는 빠른 속도를 보이는 대신에, \n과 함께 출력이 된다. 여기서 strip()이라는 매서드가 존재하는데, 이는 특정 문자열의 양 옆에 있는 개행 문자를 제거하는 역할을 한다. 따라서 다음과 같이 대체하여 사용할 수 있다.
print(sys.stdin.readline()) # Hello, world!를 입력
# Hello, world!\n
print(sys.stdin.readline().strip()) # Hello, world!를 입력
# Hello, world!
파이썬에서 input() 함수를 오버라이딩할 수 있는데 다음과 같이 기본적으로 input()을 사용하면 sys.stdin.readline을 사용할 수 있게 할 수 있다. ( 필자는 이 방법을 많이 사용한다 )
import sys
input = sys.stdin.readline
n = int(input())
li = list(map(int, input().strip()))
# 중략
백준 문제 풀이를 할 때 예시로 입력되는 값이 많지 않다면 굳이 sys.stdin.readline으로 오버라이딩 하지 않아도 괜찮지만, 설명에 따라 많은 데이터를 집어넣어야 하는 경우에는 이런 식으로 input()을 오버라이딩 하는 편이 시간 초과를 막을 수 있다.

한 블로그의 포스팅에 따르면 인풋이 10^6인 경우 다음과 같은 차이를 보인다고 한다. 이는 10배가 넘는 속도 차이이며, 0.3초 정도의 차이는 시간제한이 1초 혹은 2초 정도로 걸리는 백준 문제에서 큰 비율을 차지한다. 혹시 문제에서 시간 초과를 겪는다면, 이 선택지는 고려 사항이 아니라 필수라고 볼 수 있다.
PyPy3
백준에서 문제를 푸는 경우, 다양한 언어를 지원하는데 파이썬 계열로는 python3와 pypy3가 있다. 필자는 python3를 우선적으로 사용하는데, 가끔가다 PyPy3을 통해 풀이를 제출하는 경우가 있다. 이는 두 환경에서의 퍼포먼스 차이가 있기 때문이다.
Python3는 기본 구현체로 CPython을 사용한다. 이는 C언어로 작성되어 있으며 파이썬 코드를 바이트코드로 컴파일하여 인터프리터를 통해서 실행시킨다.
여기서 PyPy3는 JIT(Just-In-Time)이라는 개념을 도입하여 파이썬3보다 높은 퍼포먼스를 보이는데, 이는 한번에 컴파일하여 바이트코드를 실행시키는 것이 아니라, 그때그때 코드를 컴파일하여 실행시키는 것이다. 이러한 방식의 이점으로 코드를 캐싱할 수 있다는 점인데, 이러한 이유로 반복문과 같은 작업에서 높은 퍼포먼스를 보이게 된다.
따라서 백준 문제를 푼다면 일반적으로 PyPy3가 메모리와 시간 측면에서 Python3보다 높은 효율을 보인다.
보통 Python3로 풀리는 문제를 PyPy3 런타임으로 실행시키면 메모리와 시간을 보다 적게 사용할 것이다. 그런데 위와 같은 문제는 똑같은 코드를 Python3 런타임을 사용하면 시간 초과가 나고, PyPy3 런타임을 사용하면 문제가 풀린다! 이러한 경우가 있을 수 있기 때문에 정말 내 코드가 이럴리 없다... 한다면 PyPy3 런타임을 사용해 보는 것을 추천한다.

위 막대 그래프는 pypy.org에서 가져온 자료이다. 설명에 따르면 44개의 벤치마크 데이터를 통해서 위와 같은 퍼포먼스를 냈다는 것이다. 그래서 백준 문제를 푸는 도중에 시간 초과나 메모리 초과를 만나게 된다면 python 코드를 python3가 아닌 PyPy3로 제출해 보는 방법도 좋을 것이다.
여기서 들 수 있는 의문이 PyPy3를 기본으로 사용하냐 Python3을 기본으로 사용하냐인데, 필자는 Python3을 기본으로 사용한다. PyPy3 런타임이 백준 문제 풀이에서 특히 효율적인 퍼포먼스를 보이나, 밑에 설명할 sys.setrecursionlimit()를 지원하지 않는 등 Python3과 다르게 작동하는 부분이 있어서 안전성이 떨어지는 느낌이 들어 필자는 기본적으로 Python3를 통해 문제를 푼다.
sys.setrecursionlimit()
dfs(깊이 우선 탐색)과 같이 재귀를 쓴다면 위 함수로 재귀를 늘려주는 방법이 있다. 파이썬에서 기본으로 재귀 호출의 최대 깊이가 1000번으로 설정되어 있다. 따라서 다음 매서드를 통해 재귀의 횟수를 늘려주지 않으면 문제를 풀 수가 없는 경우가 있다!
import sys
sys.setrecursionlimit(10**6)
def dfs(r,c):
# 중략
위와 같이 재귀 호출의 횟수가 어느정도 될 것 같은 느낌이 들면 위 코드를 통해서 해결할 수 있다. 단 주의할 사항은 PyPy3에서는 sys.setrecursionlimit() 함수를 통해서 임의로 재귀 호출 횟수를 설정할 수 없다는 점이다.
재귀 함수를 호출하는 문제를 풀다가 의문의 런타임 에러가 발생한다면 위 코드를 참고해 보는 것이 좋을 것이다.
알아두면 좋은 입출력 코드 스타일
미로 탐색 - 입력
다음과 같이 입력이 주어진다.

위와 같은 경우에는 다음과 같이 입력을 받을 수 있다.
import sys
input = sys.stdin.readline
n,m = map(int, input().split())
board = [list(map(int,input().strip())) for _ in range(n)]
print(board)
# [[1, 0, 1, 1, 1, 1], [1, 0, 1, 0, 1, 0], [1, 0, 1, 0, 1, 1], [1, 1, 1, 0, 1, 1]]
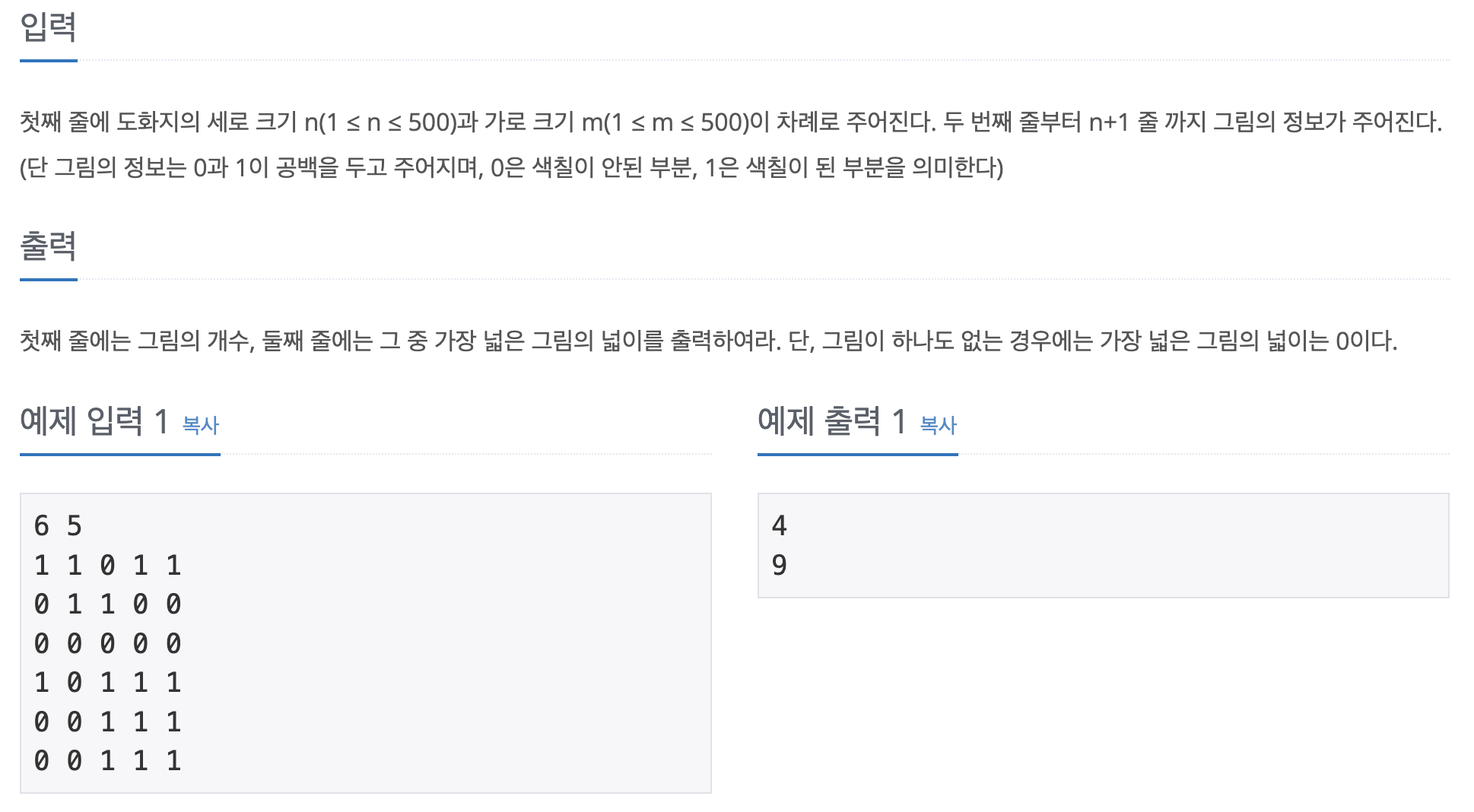
그림 - 입력
여기서는 n*m 사이즈 데이터를 줄 때, 값이 띄어져서 들어간다. 이 때는 strip()이 아닌 split()를 사용하면 된다.
import sys
input = sys.stdin.readline
n,m = map(int, input().split())
board = [list(map(int,input().split())) for _ in range(n)]
print(board)
# [[1, 1, 0, 1, 1], [0, 1, 1, 0, 0], [0, 0, 0, 0, 0], [1, 0, 1, 1, 1], [0, 0, 1, 1, 1], [0, 0, 1, 1, 1]]
간단한 리스트를 출력하는 방법
다음과 같은 join을 통해서 문자열이 들어 있는 리스트를 간단하게 한 줄로 출력할 수도 있다.
list_1 = [1,2,3,4,5]
list_2 = ['I',"love","you"]
print(''.join(map(str,list_1)))
# 12345
print(' '.join(list_2))
# I love you
위와 같은 예시들을 통해서 간단하게 입력과 출력을 받을 수 있다. 기본적인 내용이지만, 조금이라도 더 깔끔하게 입력과 출력을 받음으로써 깔끔하게 코드를 작성하기 쉬워진다.
마치며

처음으로 코딩을 시작하게 된 것이 백준 문제 풀이었다. 아마 기억을 되짚어보면 중학교 2학년 때, C언어로 처음 문제를 풀기 시작했었다. 고등학교 때는 수능을 준비하느라 아예 손을 대지 않았다.

꾸준하게 백준 문제를 푸는 것이 나름대로의 개발 능력 향상에 아주 소소하게 힘을 실어주는 것 같다고 느낀다. 물론 실제로는 라이브러리를 가져다 사용하는 위주의 개발이기 때문에, 직접적인 구현을 하게 되는 경우는 거의 없다.
참고
- [백준] CD : https://www.acmicpc.net/problem/4158
- [xhumiyu] 8 spped differences you need to know in Python : https://medium.com/@xkumiyu/8-speed-differences-you-need-to-know-in-python-db7266c3b177
- [pypy.org] spped center : https://speed.pypy.org