
아주 예전에, 학교 공지사항의 내용을 스크래핑에서 데이터베이스에 저장하고, 새로운 공지사항이 올라온 경우 사용자에게 알림을 보내는 기능을 개발한 경험이 있다. 이에 대한 내용도 포스팅을 해두었으나, 최근에 좀 더 자세하게 해당 내용을 써달라는 요청을 받기도 했고, 고생을 많이 했던 경험이 있기 때문에 보다 자세하게 해당 내용과 다양한 트러블슈팅에 대한 내용도 담으면 좋을 것 같다는 생각을 하게 되어, 좀 더 구체적으로 작성해보려고 한다.

시대생팀에서 2023년에 앱을 리빌드 하는 과정에 앞서, 기획팀원분들은 나서서 유저 리서치를 진행했습니다. 함께 유저 리서치에 참여하여 실제 사용자들은 어떤 기능을 유용하게 사용하고 있는지 함께 이야기를 나눈 적이 있습니다. 그 당시 새롭게 학교 공지사항이 올라왔을 때, 빠르게 푸시 알림으로 사용자에게 해당 내용을 전송해 주는 기능을 많은 사용자들이 유용하게 쓰고 있었고, 간헐적으로 푸시 알림이 전송되지 않는 버그가 발생하고 있었습니다. 많은 유저들이 해당 기능에 대한 불편을 호소했고, 앱을 리빌드 하는 시기에 맞춰서 공지사항을 스크래핑해서 전달해 주는 기능을 설계하기 시작했습니다.
기존 백엔드는 파이썬 언어 기반의 플라스크(Flask)를 사용하고 있었습니다. 전사적으로 이를 코틀린 언어 기반의 스프링부트(Springboot) 프레임워크로 마이그레이션하기로 결정했고, 이에 맞춰 공지사항을 스크래핑(Scraping)하는 플랫폼을 개발해야 했습니다.
공지사항을 스크래핑하는 가장 간단한 구조는 스케쥴러를 두어 공지사항 페이지를 스크래핑하는 것입니다. 하지만 이렇게 간단하게 스케쥴러를 두어 구현하는 것은 다음과 같은 문제점이 있었습니다.
- 클러스터 환경에서 2대 이상의 서버가 실행 중이면 스케쥴러가 여러 번 동작할 수 있음
- 공지사항을 정상적으로 스크래핑했다는 로그와 메인 서버의 로그가 뒤섞여 로그를 관리하기 어려움
- 학교 공지사항의 구조에 따라서 HTML을 그대로 저장해야 하는데, 스프링부트 환경에서는 다루기 어려움
이 당시 AWS의 EKS와 온프레미즈(On-premise)에 쿠버네티스 클러스터를 설치해서 서버를 운영하고 있었기 때문에, 쿠버네티스 생태계를 적극적으로 사용하려고 시도했고, 공지사항을 스크랩하는 간단한 기능은 노드(node)의 스크립트를 통해서 충분히 해결할 수 있을 것 같다는 생각에 쿠버네티스에서 시간대에 맞춰 스크립트를 실행해 주는 크론잡(cronjob)을 적극적으로 이용해서 해결하려고 했습니다.

이때 당시 스크래핑 엔진을 어떻게 구현할 수 있는지 리서치하던 도중, AWS에서 포스팅한 Serverless 방식으로 웹 크롤러를 구축하는 포스팅을 보고, 쿠버네티스 환경에서도 비슷하게 구현할 수 있을 것 같다는 생각을 했습니다. 또한 해당 포스팅은 대규모의 웹 크롤링도 소화할 수 있는 아키텍처를 설명하는 포스팅으로써, 스크래핑과 관련한 모듈을 잘게 쪼개서 관리하는 것으로 많은 이점을 얻을 수 있다는 것을 알게 되었습니다.
이를 참고하여, 하나의 공지사항 페이지(이하 오리진)를 스크래핑하는 것을 노드 스크립트로 만들어 시간대에 맞춰 동작하도록 크론잡으로 만들었고, 어떤 오리진을 스크래핑할 것인지는 쿠버네티스에서 환경 변수를 정의해 두는 컨피그맵(ConfigMap)을 사용해서 오리진을 지정할 수 있었습니다. 이러한 아키텍처를 통해서 매분 수십개의 오리진에서 안정적으로 공지사항을 받아오는 스크래퍼를 만들 수 있었습니다. 이번 포스팅에서는 이러한 아키텍처의 발전 과정과 설계하면서 느낀 다양한 고민과 해결 방안을 다루고자 합니다.
본론
문제 정의 - 어떤 기능을 구현해야할까?
스크래핑 시스템을 구축하기에 앞서 설계를 제대로 해야했습니다. 우리가 풀어야하는 문제는 다음과 같습니다. 일반공지라는 오리진을 스크래핑하려고 한다 치면, 한 페이지에 약 40개의 포스팅이 리스트로 있습니다. 그리고 각 포스팅을 클릭하면 상세 포스팅을 확인할 수 있습니다.
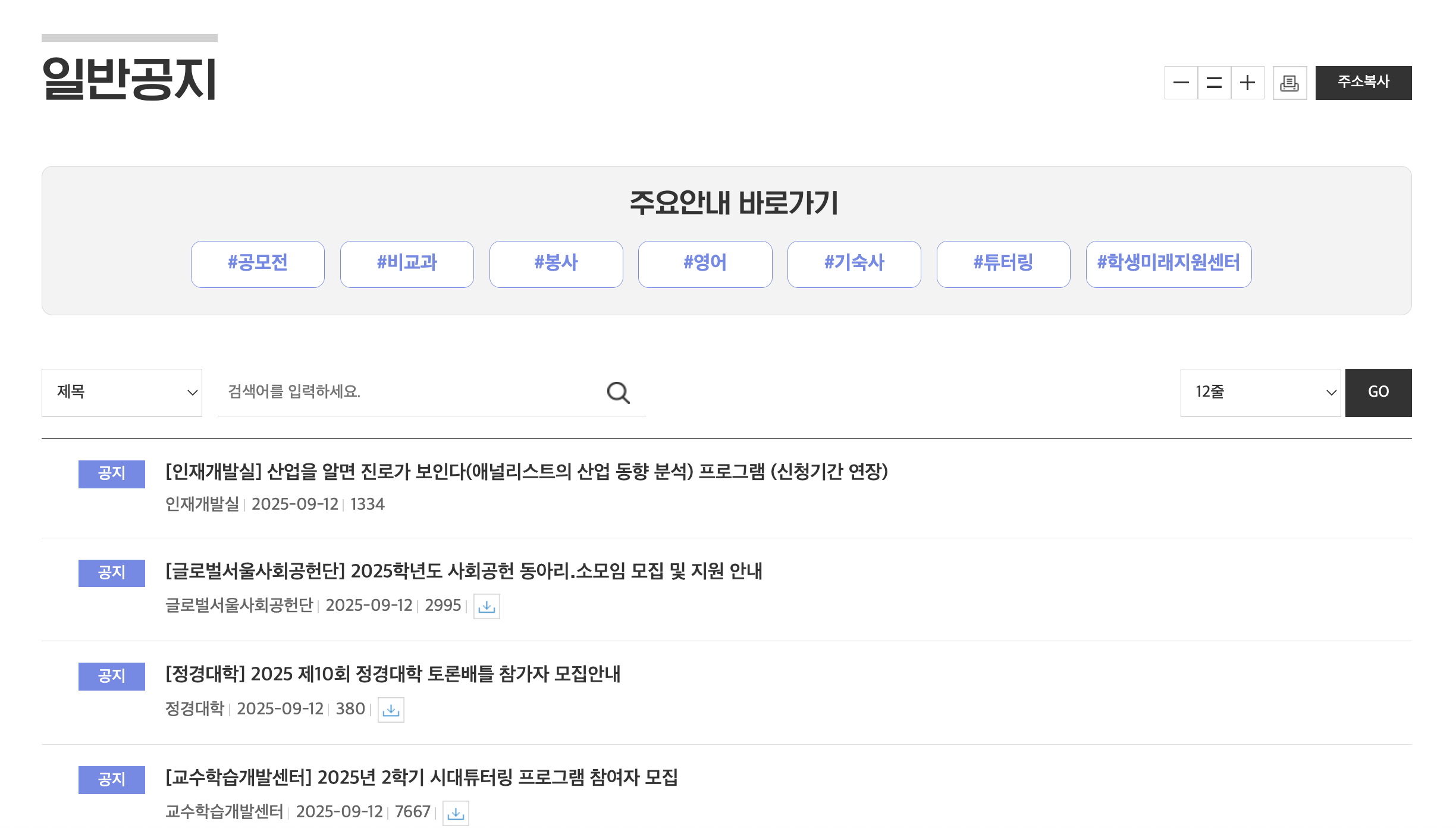
이러한 상세 페이지의 포스팅은 사진과 텍스트를 분리해서 스크래핑할 수 있는 내용이 아니었고, HTML의 내용을 그대로 가져오는 구조였기 때문에, 순수하게 메인 HTML을 가져와서 이를 보여주는 구조로 만들 수 있었습니다. 이러한 문제를 푸는 방법은 매우 간단하지만, 어떻게 이 문제를 우아하게 풀 수 있을지 고민하기 시작했습니다.
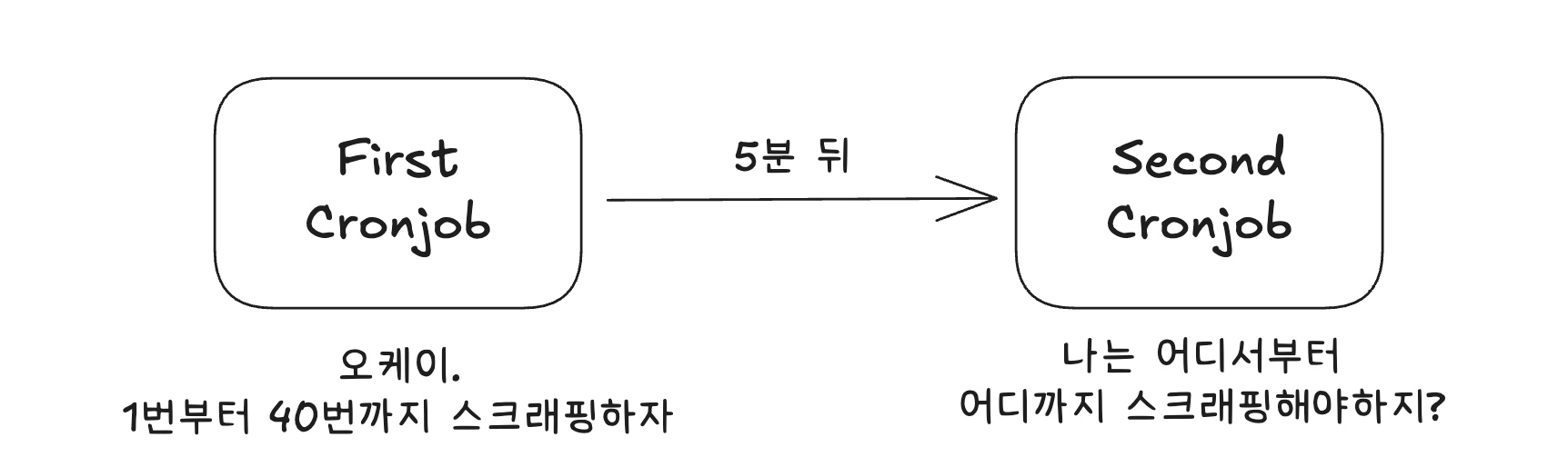
먼저, 쿠버네티스 환경에서 크론잡을 통해서 간단한 노드 스크립트를 실행하도록 하면서 가장 먼저 마주한 문제는 어디까지 스크랩했는지 상태를 어떻게 저장할 것인가? 이었습니다.
무상태(Stateless) 문제 - 어떻게 기억할 것인가
크론잡 기반의 스케쥴러 시스템을 사용하게 되면, 매번 공지사항을 스크래핑하는 작업이 무상태(stateless)인 문제가 있었습니다. 이는 서버에서 상태를 갖고 있지 않다는 뜻입니다. 쉽게 풀어서, 새롭게 실행되는 스크래퍼가 어디서부터 어디까지 스크래핑이 되었고, 앞으로는 어디를 스크래핑해야하는 지 알 수 없다는 것이었습니다.
이러한 stateless한 상태를 stateful하게 만들기 위해서는 레디스와 같은 key-value 스토어가 필요했습니다. 스토어에 어디서부터 어디까지 크롤링했는지를 넣어두고, 다음에 새롭게 뜨는 크론잡이 레디스를 참조하여 어디서부터 어디까지 크롤링이 되었는지를 확인하여, 자신이 크롤링해야하는 범위를 확인하고 작업 후에 다시 레디스에 저장하는 방식을 통해서 '서버에서 상태를 저장하여' stateful하게 문제를 해결할 수 있었습니다.

axios 기반으로 HTML을 직접 파싱해오기 위해 HTML의 트리를 확인한 결과 오리진의 각 포스팅은 유니크한 ID를 갖고 있었고, 레디스에는 이러한 포스팅의 id만을 저장하여 새로운 크론잡이 뜰 때마다 레디스를 참고하여 크롤링할 범위를 정할 수 있도록 구현을 해두었습니다. 이를 통해서 크론잡이 매번 뜰 때마다 어디까지 스크래핑했는지 확인할 수 있도록 하여, 가장 기본적인 구조로 스크래퍼를 구현하였습니다.
다음으로는, 크론잡 기반으로 만들어진 아키텍처를 확장하여 어떻게 하면 더 빠르게 더 안정적으로 유저들에게 데이터를 전달할 수 있을지 고민하기 시작했습니다.
속도와 정합성 - 최적의 아키텍처를 찾아서
두 번째 문제는 공지사항 포스팅을 스크랩하는 과정에서 시간이 오래 걸리는 경우가 간헐적으로 있다는 점입니다. 앞서, HTML을 그대로 파싱해서 저장한다고 했었는데, 그 과정에서 이미지의 URL 중에서는 엄청나게 긴 URL로 인해서 파싱해야할 데이터의 사이즈 자체가 커지는 경우가 있었습니다. 이로 인해서 속도가 느려져 레이스 컨디션(race condition)이 발생할 수 있는 상황이 있었습니다.
또한, 선착순으로 모집을 받는 공고부터 시작해서 합격자 발표와 같이 유저들에게 빠르게 전달하는 것이 중요한 공지사항들이 꽤 있었기 때문에, 거의 실시간으로 공지사항을 전달하기 위해서 매 분 크론잡을 통해서 스크래핑을 하도록 구현해야했습니다. 속도와 안정성을 모두 챙길 수 있는 아키텍처를 고민해야하는 상황이었습니다.
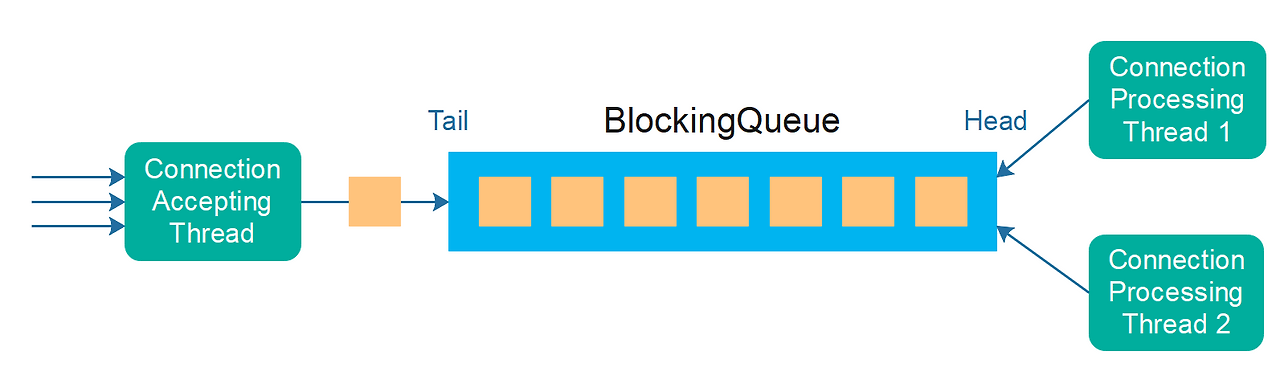
가장 좋은 방법은 빠르게 어디까지 스크래핑해야하는지 확인하는 동기적인 역할과 스크래핑해야하는 페이지를 파싱하는 것을 비동기로 분리하는 것이었습니다. 이를 해결하기 위해서 프로듀서(Producer)와 컨슈머(Consumer)의 개념을 사용했습니다.
레디스는 다양한 자료형을 지원하는데, 그 중의 하나가 레디스를 큐(queue)로 사용할 수 있다는 점입니다. 이를 통해서 레디스를 큐로 사용하여, 프로듀서는 공지사항의 한 페이지에 들어있는 약 40개의 공지사항 중, ID가 중복되지 않는 것들만 큐에 집어넣고, 각각의 상세 페이지의 HTML을 파싱하는 작업은 컨슈머가 비동기적으로 처리하도록 구성했습니다.
이와 관련하여 레디스를 통해서 다양한 정보들을 저장할 수 있었는데, 이 과정에서 어떻게 하면 최대한 안정적이고, 효율적으로 큐를 쓸 수 있을까?라는 고민을 많이 했습니다. 이 당시에 AWS에서 포스팅한 대규모 웹 크롤러 아키텍처를 참고하여, 높은 정합성을 보장하는 아키텍처를 비슷하게 구현할 수 있었습니다.
- [Amazon] https://aws.amazon.com/ko/blogs/architecture/scaling-up-a-serverless-web-crawler-and-search-engine/
해당 포스팅에서 제시하는 웹 크롤러가 레디스와 같은 스토어를 참조하면서 작업을 진행하는 과정을 플로우 차트로 나타내면 다음과 같습니다. 다음의 구조도는 위의 포스팅에서 가져온 이미지입니다.
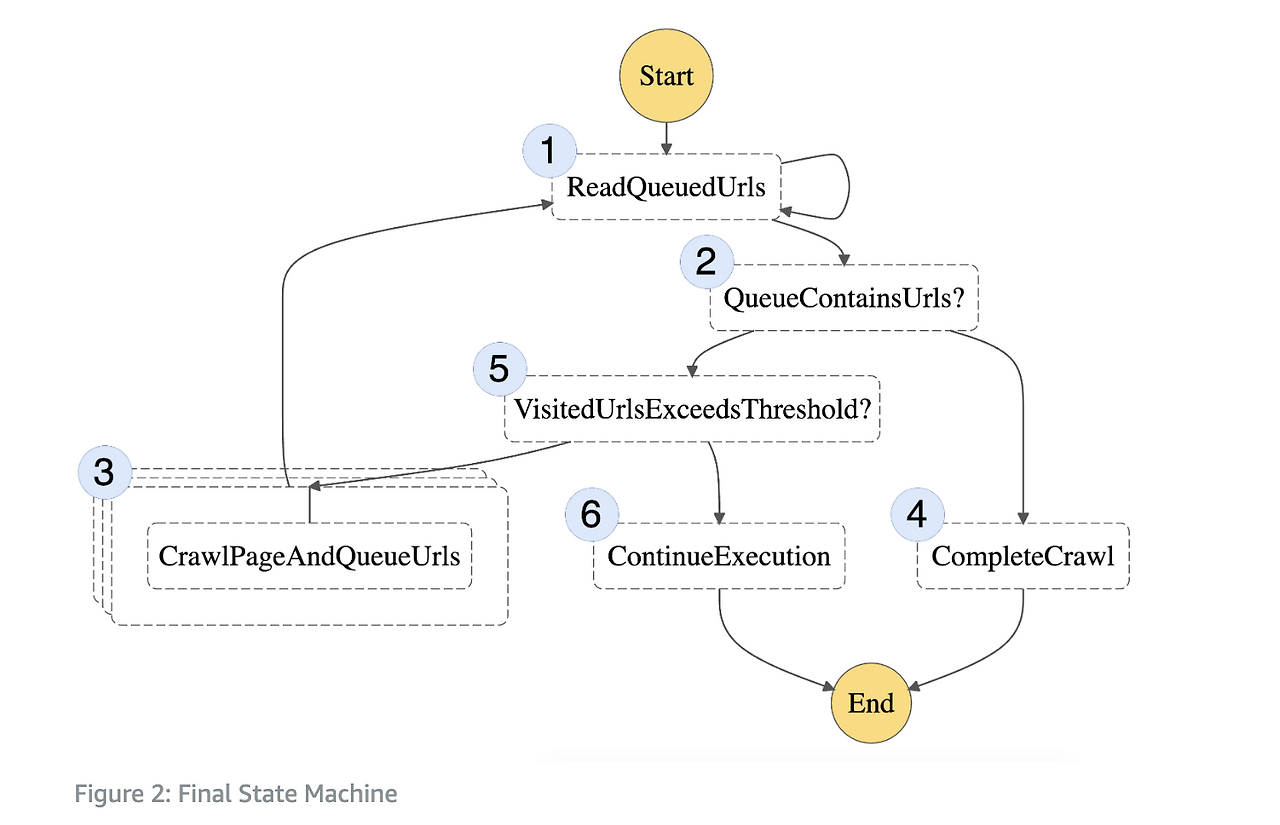
위와 같은 구조를 통해서, 프로듀서와 컨슈머의 구조를 통해서 매분마다 올라오는 공지사항을 전달하는 아키텍처의 구현은 끝났습니다. 다음으로는 안정성에 대한 의문을 품기 시작했습니다. 정합성을 중요하게 생각한 이유는, 갑자기 다량의 중복된 데이터가 혹여나 생긴다면 의도치 않게 다량의 푸시 알림이 전송되면 유저들에게 큰 어뷰징을 초래할 수 있고, 유저가 급격하게 몰리면서 서버가 다운되고 장애가 전파될 수 있기 때문입니다.
따라서, 여러 문제가 될 수 있는 상황을 고민하여, 문제가 발생하더라도 피해를 최소화할 수 있는 아키텍처를 구현할 수 있지 않을까? 라는 고민에서 사소한 수정 하나만으로 유저들에게 다량의 푸시알림이 발생할 수도 있는 문제를 막기 위해 고민했습니다.
멱등성 - 실패를 하더라도 딛고 일어설 수 있게
마지막 문제는 멱등성(Idempotency)를 보장하는 것이었습니다. 멱등성을 보장하는 부분은 다름이 아니라 유저들에게 푸시 알림을 보내는 로직이었습니다. 컨슈머가 정상적으로 상세 페이지를 파싱하는 경우 이를 메인 서버에 웹훅을 보내서 유저들에게 푸시알림을 보내주는 구조입니다.

여기서 발생할 수 있는 문제점은 만약에 레디스가 다운되어 스크래퍼가 중복된 데이터를 메인 서버로 웹훅을 보내는 경우에, 심각한 어뷰징을 초래할 수 있는 점입니다. 당시 서버 비용의 문제와 교내 공지사항 스크래핑의 속도를 위해서 내부망에 위치한 학교 서버에 온프레미즈로 쿠버네티스를 사용하기도 했었는데, 이 때 네트워크의 문제나 메모리의 문제로 서버가 불안정하기도 했습니다.
이러한 점을 고려하여 중복된 데이터가 유저들에게 전송되지 않도록 메인 서버에서는 멱등성을 구현하였습니다. 즉, 똑같은 웹훅이 여러번 오더라도 메인 서버의 상태는 똑같아야 합니다. 1번이 오더라도, 2번이 오더라도, 10번이 오더라도 같은 상태를 유지해야했습니다. 이를 위해서 컨슈머가 웹훅을 보내는 경우 공지사항의 유니크한 ID를 보내주도록 하여, 데이터베이스의 공지사항 테이블에서는 이 공지사항의 ID를 유니크 키(Unique Key)로 사용하도록 설정하였습니다.
그리고 나서는, 웹훅을 발송하는 서버의 로직을 웹훅 수신 -> 웹훅 발송 -> 데이터베이스 저장이 아닌, 순서를 바꿔 웹훅 수신 -> 데이터베이스 저장 -> 웹훅 발송으로 순서를 수정할 수 있었습니다. 앞서 설명한 컨슈머가 상세 페이지를 스크래핑해서 웹훅 서버로 보내는 경우에는 해당 페이지의 URL을 전송합니다. 이를 유니크 키(Unique Key)로 설정하고 있었기 때문에, 만약에 같은 URL을 스크래핑하는 경우 데이터베이스의 유니크 키 제약 조건으로 인해서 데이터베이스에 저장되지 않고 에러를 발생시키며, 당연히 웹훅 발송 또한 되지 않도록 하였습니다.
이러한 고민 끝에 실제로 레디스 파드(pod)를 삭제해도 푸시 알림 어뷰징이 없는 것을 확인하였고, 1년 365일 작동시켜도 안심할 수 있을만한 아키텍처를 구현할 수 있었습니다. 실제로 공지사항 기능은 출시되고난 후에도 꾸준히 유저들의 사랑을 받았습니다.
마치며
개인적으로, 제일 재미있게 했었던 프로젝트 경험을 꼽으라고 하면 아마도 이 스크래퍼 개발이 아닐까 합니다. 쿠버네티스의 세계에 발을 디딜 수 있었던 프로젝트이며, 프레임워크 기반의 사고방식에서 확장하여, 레디스나 스크립트, 그리고 웹훅까지 기술적인 세계관을 많이 확장할 수 있었던 프로젝트입니다.
그만큼 많이 힘들었기 때문에 기억에도 많이 남으며, 이때만큼 치열하게 고민할 수 있었던 경험이 많지 않았던 것 같습니다.
'DevOps > kubernetes' 카테고리의 다른 글
| istio gateway란 무엇인가? (1) | 2025.12.15 |
|---|---|
| 온프레미스 쿠버네티스에서 쓰이는 MetalLB (1) | 2025.11.29 |
| [CKA] 기출 문제 정리 (0) | 2025.01.12 |
| 쿠버네티스의 Kustomize에 대해서 (1) | 2024.12.20 |
| ETCD Leader Election이란? (1) | 2024.12.18 |